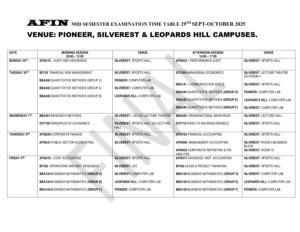
Data cleaning is essential for effective data analysis and decision-making. This tutorial provides a step-by-step approach to cleaning messy datasets using Python and pandas. Topics covered include handling missing values, standardizing formats, and removing duplicates. Ideal for data science students and professionals looking to enhance their data preparation skills. Learn practical techniques to ensure data integrity and improve analysis outcomes.
Key Points
- Covers essential data cleaning techniques using Python and pandas.
- Explains how to handle missing values and standardize data formats.
- Includes practical examples for removing duplicates in datasets.
- Ideal for data science students and professionals seeking to improve data quality.