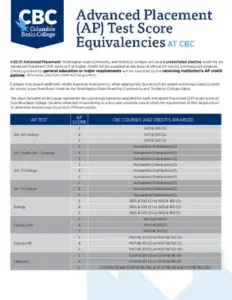
The ML Test Score:
A Rubric for ML Production Readiness and Technical Debt Reduction
Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, D. Sculley
Google, Inc.
ebreck, cais, nielsene, msalib, dsculley@google.com
Abstract—Creating reliable, production-level machine learn-
ing systems brings on a host of concerns not found in
small toy examples or even large offline research experiments.
Testing and monitoring are key considerations for ensuring
the production-readiness of an ML system, and for reducing
technical debt of ML systems. But it can be difficult to formu-
late specific tests, given that the actual prediction behavior of
any given model is difficult to specify a priori. In this paper,
we present 28 specific tests and monitoring needs, drawn from
experience with a wide range of production ML systems to help
quantify these issues and present an easy to follow road-map
to improve production readiness and pay down ML technical
debt.
Keywords-Machine Learning, Testing, Monitoring, Reliabil-
ity, Best Practices, Technical Debt
I. INTRODUCTION
As machine learning (ML) systems continue to take on
ever more central roles in real-world production settings,
the issue of ML reliability has become increasingly critical.
ML reliability involves a host of issues not found in small
toy examples or even large offline experiments, which can
lead to surprisingly large amounts of technical debt [1].
Testing and monitoring are important strategies for improv-
ing reliability, reducing technical debt, and lowering long-
term maintenance cost. However, as suggested by Figure
1, ML system testing is also more complex a challenge
than testing manually coded systems, due to the fact that
ML system behavior depends strongly on data and models
that cannot be strongly specified a priori. One way to see
this is to consider ML training as analogous to compilation,
where the source is both code and training data. By that
analogy, training data needs testing like code, and a trained
ML model needs production practices like a binary does,
such as debuggability, rollbacks and monitoring.
So, what should be tested and how much is enough?
In this paper, we try to answer this question with a test
rubric, which is based on engineering decades of production-
level ML systems at Google, in systems such as ad click
prediction [2] and the Sibyl ML platform [3].
We present a rubric as a set of 28 actionable tests, and
offer a scoring system to measure how ready for production
a given machine learning system is. This rubric is intended
to cover a range from a team just starting out with machine
learning up through tests that even a well-established team
may find difficult. Note that this rubric focuses on issues
specific to ML systems, and so does not include generic
software engineering best practices such as ensuring good
unit test coverage and a well-defined binary release process.
Such strategies remain necessary as well. We do call out
a few specific areas for unit or integration tests that have
unique ML-related behavior.
How to read the tests: Each test is written as an
assertion; our recommendation is to test that the assertion is
true, the more frequently the better, and to fix the system if
the assertion is not true.
Doesn’t this all go without saying?: Before we enu-
merate our suggested tests, we should address one objection
the reader may have – obviously one should write tests for
an engineering project! While this is true in principle, in a
survey of several dozen teams at Google, none of these tests
was implemented by more than 80% of teams (though, even
in a engineering culture valuing rigorous testing, many of
these ML-centric tests are non-obvious). Conversely, most
tests had a nonzero score for at least half of the teams
surveyed; our tests do represent practices that teams find
to be worth doing.
In this paper, we are largely concerned with supervised
ML systems that are trained continuously online and perform
rapid, low-latency inference on a server. Features are often
derived from large amounts of data such as streaming logs
of incoming data. However, most of our recommendations
apply to other forms of ML systems, such as infrequently
trained models pushed to client-side systems for inference.
A. Related work
Software testing is well studied, as is machine learning,
but their intersection has been less well explored in the
literature. [4] reviews testing for scientific software more
generally, and cites a number of articles such as [5], who
present an approach for testing ML algorithms. These ideas
are a useful complement for the tests we present, which are
focused on testing the use of ML in a production system
rather than just the correctness of the ML algorithm per se.
Zinkevich provides extensive advice on building effective
machine learning models in real world systems [6]. Those
rules are complementary to this rubric, which is more
c
2017 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media,
including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to
servers or lists, or reuse of any copyrighted component of this work in other works. Published as [7].