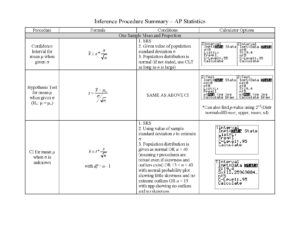
Interval Estimation
In a statistics examination for secondary students, the 22 females used in the study has a mean score of 81 and a
variance of 12 while the 20 males used has a mean score of 78 and a variance of 10. Do you think gender have an
effect on the score of these secondary students at ∝= 0.05and ∝= 0.01?
40
Using brandP petrol for the mean number of kilometres covered by 22 similar kekemarwa were 52.5𝑘𝑘𝑘𝑘 with
standard deviation of 7.0. Using brand Q petrol, the mean was 51km with standard deviation of 7.5. Using
significance level of 0.05, is there any reason to belief that brand P is better than brand Q?
42
Sampling where each member of the population may be chosen more than once is called
sampling with replacement
sampling where each member cannot be chosen more than once is called sampling without replacement.
The values of a population parameter and that of the corresponding statistic are not always the same. If a difference
occurs this difference is known as a
sampling error
sampling error (E) is defined as the difference between the sample statistic (s) and the population parameter being
estimated (P)
A sampling distribution is the set of all possible values of a particular statistic and you should note that there is
sampling distribution of means, sampling distribution of variance, etc.
A graph for frequency distribution can be supplied by a histogram or by a polygon graph often called a
frequency polygon
A t-test is any statistical test in which the test statistic follows a student’s t distribution if the null hypothesis is
supported
T-test is used to compare two different set of values. It is generally performed on a small set of data
The T statistic was introduced in 1908 by William Sealy Gosse
Two-sample t-tests for a difference in mean involve independent samples and overlapping samples.
The paired t-tests are of form of blocking and have greater power than unpaired tests when the paired units are
similar with respect to noise factors that are independent of membership in the two groups being compared.
The independent samples t-test is used when two separates sets of independent and identically distributed
samples are obtained, one from each of the two populations being compared.
Paired samples t-tests consist of a simple of matched pairs of similar units, or one group of units that has been
tested twice which sometimes we call repeated measures t-test
is a statistical test that is applied to categorical data to investigate how likely it is that any observed difference
between the sets arose by chance and it is good for unpaired data that can be seen from large samples.
Pearson’s Chi-Square Test
is used to assess the two types “test of goodness of fit” and tests of independence
Pearson’s Chi-Square Test